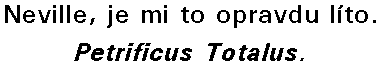 -c 255,255,0,255 |
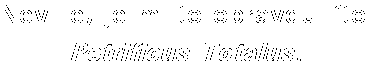 -c 255,0,255,255 |
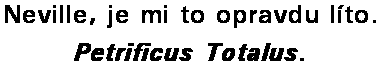 -c 255,0,0,255 |
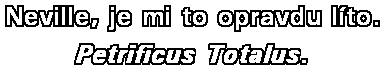 -c 0,255,255,255 |
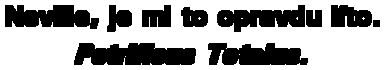 -c 0,0,0,255 |
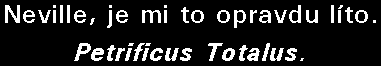 -c 0,0,255,0 |
Tato záležitost představuje nejpracnější část převodu filmu z DVD na CD, alespoň co se Linuxu týče. Jak
jsem psal už dříve,
tak titulky jsou na DVD uloženy společně s videem a audiem a sice jako obrázky (což je velmi praktické - nenastávají potíže
s fonty, zejm. těmi problematickými jako jsou čeština, azbuka, asijské jazyky atp.).
Pokud máte na počítači nainstalován vedle Linuxu taky MS Windows, pak si můžete trochu usnadnit práci - přečtěte si
sekci DVD-Linux-Windows-TXT titulky na konci tohoto článku.
Nejdříve si připravíme potřebný software. Budeme potřebovat:
Tenhle prográmek je součástí balíčku transcode. Jedním ze způsobů jak zjistit, jestli ho máme nainstalovaný a jakou verzi, je v konzoli zadat
rpm -qa | grep transcodenebo prostě man transcode. tcextract slouží k extrakci požadovaného proudu (stopy) z multimediálního souboru. V našem případě nám vytáhne z DVD filmu požadované titulky.
Zdrojový kód tohoto programu je součástí zdrojového balíčku transcode a najdete ho tam v podadresáři /contrib/subrip/. Zde
se přesuňte a zadejte make. Z výsledku budeme potřebovat jen subtitle2pgm.
Program převádí vstupní soubor formátu z tcextract na posloupnost obrázků formátu pgm, které obsahují
černobílé titulky.
subtitle2pgm potřebuje ke své činnosti knihovnu libnetpbm, tak si ji případně doinstalujte z instalačních CD (já jsem použil libnetpbm9-9.24-4mdk pro MandrakeLinux 9.0).
Tenhle program nám pro naše účely plnohodnotně nahradí GOCR (GNU Optical Character Recognition). Ba co víc, tím,
že si ho Martin Kačer napsal právě pro účely převodu titulků z DVD do textové podoby, je sice úzce zaměřený
na jedinou činnost, zato ale pracuje daleko spolehlivěji než GOCR a hlavně bez problémů zvládá češtinu. Program
využívá toho, že všechna stejná písmenka vypadají v DVD titulcích naprosto stejně (italics/kurzíva, velká písmena
a malá písmena však představují samostatné znakové sady). Program se postupně ptá na jednotlivě rozpoznané znaky,
jejich přiřazení si v průběhu jednoho zpracování pamatuje. Programu tak musíme říct, jaké znaky reprezentuje cca 100
postupně rozpoznaných vzorků (3*26 + číslice + další znaky + slitá písmena zejm. u kurzívy).
Software získáte ze stránky projektu (projekt se původně
jmenoval DVDtit, ale jeho současný oficiální název je DVDSub). Nebo vám jeho
rannou (ale plně dostačující) verzi můžu zaslat mailem - je to v podstatě jeden soubor (zdroják programu v Céčku)
v tar.gzip archivu o velikosti 7kB. Po jeho rozbalení (tar xfvz dvdtit.tgz) zadáte jen
gcc dvdtit.c -o dvdsubpro zkompilování a výsledný program se bude jmenovat dvdsub
V prvním kroku musíme z DVD videa vytáhnout odpovídající stopu příslušných titulků (zde odkazuji na můj předchozí článek o ripování z DVD přes MPlayer/MEncoder). K tomu využijeme tcextract. Pokud jste si už video stáhli (dekryptovali) z DVD na disk přes
mplayer -dvd 1 -dumpstream -dumpfile Jmeno_filmu.dumpstreamtak zadejte
tcextract -i Jmeno_filmu.dumpstream -x ps1 \
-a 0x2? > Jmeno_filmu.titulky
Parametry:
Pokud chcete vytáhnout titulky přímo z DVD disku, pak použijte rouru
tccat -i /dev/dvd -T 1 -L | tcextract -x ps1 -t vob \
-a 0x2? > Jmeno_filmu.titulky
Parametry:
Výsledný soubor Jmeno_filmu.titulky bude mít několik MB (1-5 podle rozsahu titulků). Doporučuji vytvořit nový adresář a do něj tento soubor přesunout společně s programy subtitle2pgm a dvdsub. Nyní přistoupíme k převedení 'titulkového proudu' na sekvenci obrázků pro následné optické rozpoznávání textu:
./subtitle2pgm -i Jmeno_filmu.titulky -o titulky -c 255,0,0,255 -C 5Nejdřív trošku teorie :o) Pokud se nemýlím, tak v DVD titulcích jsou povoleny 4 barvy - odstíny šedé. To umožňuje, aby byly titulky vyhlazenější s obrysy jiného odstínu (v MPlayeru navíc mají lehký nádech pozadí, na němž jsou umístěny , takže titulky v něm je opravdu radost číst :-). Pro co nejspolehlivější optické rozpoznání textu potřebujeme co možná nejvýraznější text v grafické podobě. Nahradíme tedy některé odstíny šedi černou, jiné bílou. I tohle umí subtitle2pgm.
Parametry:
Následující obrázky zachycují český titulek č.1004 z DVD Harry Potter a kámen mudrců. Orámování obrázků jsem přidal pro lepší představu o jejich velikosti a funkčnosti parametru -C 5. "Spojením" 1. a 2. varianty dostáváme tlustší titulky ve 3.variantě. To se ale nakonec ukázalo jako ne moc šťastné, protože se pro software (dvdsub) slévaly písmena u kurzívy. Když pak ještě k variantě 3. přidáte 4.kombinaci, vzejdou vám nečitelné titulky jako na 5.ukázce. 6.obrázek si analyzujte sami. Kdo má dobré oči a plochý monitor, tak si určitě všimne, že jednotlivé varianty mají různé rozměry - na tom zapracoval právě parametr -C 5.
-c 255,255,0,255 |
-c 255,0,255,255 |
-c 255,0,0,255 |
-c 0,255,255,255 |
-c 0,0,0,255 |
-c 0,0,255,0 |
./dvdsub titulky.srtxa program začne pracovat. Postupně se vás bude ptát na jednotlivé rozpoznané znaky. Nespěchejte, raději si pozorně prohlédněte, co že je to za písmenko popř. jejich shluk (zejména u kurzívy). Na následujícím obrázku (pro zvětšení na něj klikněte) vidíte jeden z problémů - program nerozlišil jednotlivé znaky, ale ptá se na celou jejich sekvenci. V takovém případě je vypište do dialogového řádku všechny a potvrďte ENTERem. Ukázka z dvdsub koresponduje s výše uvedenými titulky - jedná se o písmena Pe a trific ze slova Petrificus.

POZOR! Nezapomeňte, že během práce s dvdsub budete potřebovat českou klávesnici pro znaky s diakritikou.
Program dvdsub doběhl do konce a my máme textové titulky v souboru dvdsub.output, kde jsou uloženy ve formátu SRT. Pokud chcete mít titulky naprosto bezchybné, nezbývá, než je "ručně" projít a opravit případné chyby. Některé z nich lze opravit automaticky buď v textovém editoru nebo proudovým editorem sed za použití vhodných regulárních výrazů:
sed -e "s/''/\"/g" dvdsub.output > titulky1.srt
sed -e "s/\ \././g" titulky1.srt > titulky2.srt sed -e "s/\ ,/,/g" titulky2.srt > titulky3.srt
sed -e "s/d'/ď/g" titulky3.srt > titulky4.srt sed -e "s/t'/ť/g" titulky4.srt > titulky5.srt
???
Posledním, alternativním krokem je vyjít vstříc kolegům s neUnixovou platformou tím, že převedeme titulky ze znakové sady ISO-8859-2 do CP1250 (Windows-středoevropské) popř. jiné:
recode ISO-8859-2..CP1250 < Titulky_ISO2.srt > Titulky_CP1250.srtA pokud si někdo chce převést titulky z formátu SRT do snad běžnějšího a úspornějšího MicroDVD (.sub), pak já k tomu používám MPlayer (bohužel se nevyhneme potřebě nějakého multimediálního souboru):
mplayer Multimedialni_soubor -sub Nazev_titulku_v_SRT -dumpmicrodvdsubMPlayer vytvoří druhý soubor titulků dumpsub.sub, ještě než začne přehrávat, takže jakmile se objeví obraz, můžeme přehrávání ukončit.
Pokud máte z jakéhokoli důvodu tak jako já na stroji nainstalovány vedle Linuxu taky Wokna, pak můžete využít "kooperace"
MPlayeru (z Linuxu) a již zmíněného programu SubRip (já používám verzi 1.06) pro Windows - stáhnout se dá z Internetu,
je to GNU GPL projekt v Delphi; instalační .exe má 700kB.
A proč to dělat takhle složitě? Pokud váš počítač nebootuje věčnost, pak ušetříte čas strávený nad sháněním a instalací tcextract,
subtitle2pgm a dvdsub. SubRip nevyžaduje mezikrok rozložení 'titulkového proudu' do obrázků. Vyhnete se taky psaní v konzoli. Počítám,
že tuto možnost využijou jen začátečníci v Linuxu. A proč neudělat titulky celé přes Windows? Program SubRip (ostatně stejně
jako každý jiný software pro práci s DVD) potřebuje dekryptovaná data. Pokud pustíte SubRip přímo na DVD disk, vyláme si zuby,
pokud je DVD kryptováno (v drtivé většině případů).
Nejdříve v Linuxu vytáhneme z filmu (již dříve připraveného dumpstreamu z DVD disku - dekryptování) pomocí mencoderu požadované titulky
do formátu vobsub:
mencoder Nazev_filmu.dumpstream -sid 2 -ovc frameno -nosound \
-o /dev/null -vobsubout Nazev_titulku
Výsledkem budou dva soubory Nazev_titulku.sub (obsahje titulky ve formátu vobsub) a Nazev_titulku.idx (obsahuje indexy
pro titulky). Oba soubory (celkem několik MB) překopírujte/přesuňte na windows partition, abychom na ně z Windows dosáhli.
Parametry:
![]()
