
This software (as the others mine) is free software; it can be freely distributed and/or modified under terms of GNU General Public Licence published by Free Software Foundation (version 2 or later).
I have started this project in 2003. My first script in Perl concerning DVD subtitles was srtrepair designated for SRT subtitles timing and text corrections. When I have started to rip DVDs some tool for DVD subtitle stream conversion into TXT was needed. Once I tried gocr - it has disappointed me at all. It was unable to catch Czech diacritical letters. Then I used for some time Martin Kacer's dvdsub written in C++, but in it's early stage it was very primitive and unable to handle italics. So I decided to write my own exact match OCR (Optical Character Recognition) software pgm2srt (it processes series of PGM pictures containing subtitles into SRT subtitles text format). Perhaps Perl was not the best way but I had just learnt it so I wanted to try. So the console script was born. Some time passed, I have become lazy :o) and here we are - I've started to work on GUI (Graphical User Interface) for pgm2srt, which I called gpgm2srt. gpgm2srt is completely rewritten code of pgm2srt. It was divided into 2 scripts - Exactocr.pm containing the core exact match OCR algorithm and gpgm2srt.pl containing the rest of GUI. Compared to pgm2srt, gpgm2srt adds far more functionality and makes the process of DVD subtitles conversion into SRT format much more compact, complex and comfortable :o)
As all herein mentioned programs also gpgm2srt is a Perl script. It is plain text file containing commands that need to be interpreted/executed by PERL installed in operating system. Compared to console version gpgm2srt needs also Perl-Tk graphical toolkit incorporating miscellaneous graphical widgets (window, buttons, scrollbars, canvas etc.). Software requirements are:
| ! | Perl | Perl interpreter, version 5.8 or higher is recommended |
| ! | Perl-Tk | Perl graphical toolkit |
| ! | subtitle2pgm | binary file compiled out of transcode sources; version compiled on Mandrake(Mandriva)Linux is for download; it should work under other Linux distributions too (try subtitle2pgm -h in location directory, it prints help); this binary converts subtitles stream into series of PGM pictures + .srtx file containing timing |
| ! | libnetpbm9 | library needed for PBM/PGM/PPM/PNM graphical formats manipulation and required by subtitle2pgm; whether is the library present in system type rpm -qa | grep pbm on systems using RPM packages. In case of need, as root use rpm -ivh libnetpbm9-9.24-8mdk.i586.rpm |
| !? | perl-Tie-Watch | depending on your distribution this package for Perl could be required |
| !? | recode | utility from same package for conversion of text between different code pages |
| !? | file | utility from same package for file type detection – in case of textual file it prints also encoding (code page) used |
| ? | tcextract | program from transcode package used for extracting subtitles stream out of multimedia file (DVD) |
| ? | tccat | program from transcode package used for DVD content reading |
| ? | MPlayer | multimedia player used by script for listing subtitles included on DVD (which subtitle languages are present on DVD) |
| ? | srtrepair.pl | own Perl script for timing and text corrections after OCR; version 1.10 required (the most recent is recommended) |
Only single scripts (no rpm) gpgm2srt.pl and Exactocr.pm are available currently (you can find them in the download section). The latter mentioned script is a perl module incorporating the exact match OCR (Optical Character Recognition) algorithm common both for graphical and console version in the future. Thus separate upgrades are possible. Henceforth the console script pgm2srt.pl is unmaintained. The Exactocr.pm module is massively based on pgm2srt.pl.
Download gpgm2srt.pl and Exactocr.pm scripts together with subtitle2pgm into ~/bin/ directory, i.e. your home directory - in my case it is /home/hanus/bin/. If /bin/ directory is not present in your home directory, create it. Then type echo $PATH and check, whether the directory /home/user/bin/ is set for commands search. If not, use PATH=$PATH:$HOME/bin to set it.
Older Perl versions can file to compile use encoding ':locale'; command. In such case either comment the line with #, or in prompt use
sed "s/use encoding/#use encoding/" -i gpgm2srt.plSame approach can be tried in case of problems with saving/loading text subtitles encoded in UTF-8/ISO-2/Win1250.
Script processes subtitles saved as sequence of black-and-white PNG pictures, which is the output of subtitle2pgm application on subtitle stream. Other output is .srtx file containing subtitles timing. You can get subtitle stream from DVD disc using tcextract (together with use of MPlayer or tccat). The procedure of doing this can be found in my previous article on processing DVD subtitles in console. gpgm2srt offers the same functionality through several clicks with ease of graphical interface and additionally supplies more features.
Scripts are still under development, lots of features are not yet implemented (see TO DO section at the end), but the functionality is already pretty good. Any bug reports and requests for features are highly welcome.
At the moment only English version of GUI is available. But the recognition algorithm is designed with diacritics capabilities, so "no problem" with Czech, Slovak etc.
If the program runs oddly or not at all, run it from console and watch/send the appearing messages. Remember that the program is only a script, so the speed is limited (but Perl's compiled scripts run pretty fast). On my 1.8Ghz Pentium 4 is the script fast enough. If something takes a little more time, please be patient. But of course it can freeze (unhandled loop etc.) - watch the messages in console, processor load and hard disc activity (e.g. using gkrellm or other such a tool). If the processor runs on 100% for longer time, disk shows no activity and there is no action in the script's window, it got looped :o) But it shouldn't happen in this stage of my exact match OCR algorithm version. The most time-intensive is the initial subtitle stream ripping from DVD disc and then the conversion of subtitle stream into PGM pictures (using pgm2subtitles).
The whole process of DVD subtitles conversion into text format is divided into several steps, each step is represented by one tab. Finalization of processes in one tab activates the subsequent one (exceptionally more tabs are available at the same moment). At the beginning two tabs are active - Extract subtitles stream and Files and Paths. There are two ways to start the process - either you have already prepared subtitle stream, then go directly to Files and Paths tab, or you need firstly extract subtitle stream from DVD or multimedia file - then use the first tab Extract subtitles stream.
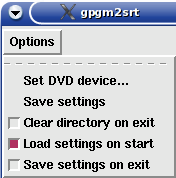 When you run the script for the first time it may be necessary to set DVD device to enable MPlayer get list
of available subtitles on the DVD disc. To do this use Options menu as shown in the picture. Default
setting is /dev/dvd. Save settings in Options menu immediately saves the current settings - it
is stored in hidden file .gpgm2srt.conf in user's home directory, particular items are commented.
Activating Clear directory causes the script to delete its working directory .gpgm2srt
in user's home directory (exactly only .pgm .srtx .source files are deleted). But then you can't
check problems comparing text subtitle with picture subtitle.
Switch Load settings on start activates configuration loading on script start (so default settings are
overridden). Switch Save settings on exit activates configuration saving on script end; inactive switch
causes the settings to be lost after script end unless you use item Save settings that saves the configuration
immediately.
In case you set something wrong and want the defaults back, end script and delete the config file
.gpgm2srt.conf, then run script again.
When you run the script for the first time it may be necessary to set DVD device to enable MPlayer get list
of available subtitles on the DVD disc. To do this use Options menu as shown in the picture. Default
setting is /dev/dvd. Save settings in Options menu immediately saves the current settings - it
is stored in hidden file .gpgm2srt.conf in user's home directory, particular items are commented.
Activating Clear directory causes the script to delete its working directory .gpgm2srt
in user's home directory (exactly only .pgm .srtx .source files are deleted). But then you can't
check problems comparing text subtitle with picture subtitle.
Switch Load settings on start activates configuration loading on script start (so default settings are
overridden). Switch Save settings on exit activates configuration saving on script end; inactive switch
causes the settings to be lost after script end unless you use item Save settings that saves the configuration
immediately.
In case you set something wrong and want the defaults back, end script and delete the config file
.gpgm2srt.conf, then run script again.
The first tab Extract subtitles stream is appointed for extracting subtitle stream from DVD disc or previously created DVD image stored on disk (e.g. MPlayer's option -dumpstream, see my article about DVD ripping /in Czech/).
If MPlayer is installed, DVD device properly set and DVD disc inserted you can set DVD Title in Subtitles stream check area and press Check DVD for subtitles to look for subtitle streams available for given DVD title. The result is displayed in Subtitles list frame. The picture below shows Italian subtitles with code 0, French with code 1, German with code 2 etc. If selected DVD title contains no subtitle stream or DVD could not be read the text No subtitles found is displayed.
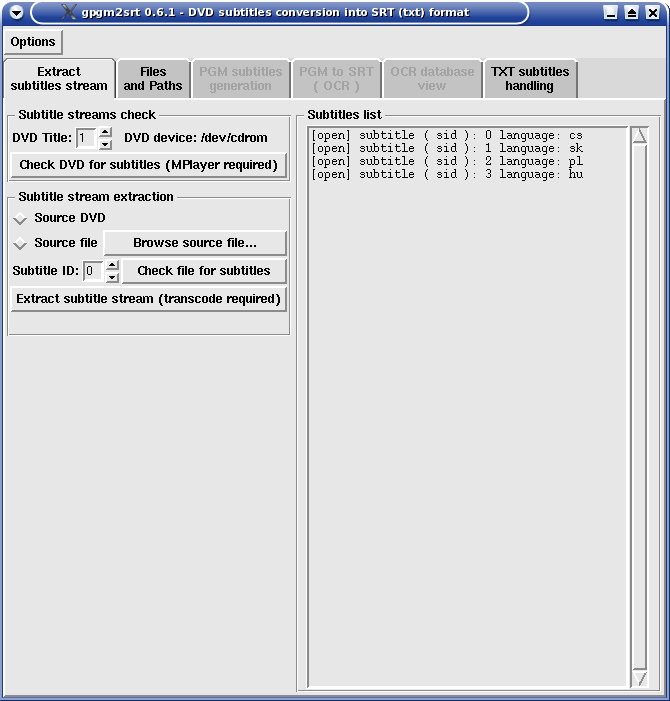
When you know the subtitles code (ID) which you want to be extracted, move to Subtitle stream extraction
bloc. If you have previously checked DVD for subtitles stream content Source DVD will be automatically selected.
In case you want to extract subtitle stream from file stored on hard disk click Browse source file... and
select demanded multimedia file containing subtitle stream; Source file will be selected. Sometimes
Perl-Tk OpenFile dialog fails and the file must be selected once again.
Now you have to set Subtitle ID: (subtitles stream code). Finally click Extract subtitle stream button.
Text appears under the button asking you for patience - the extraction will take some minutes depending
on power of your machine. The processor, DVD drive and disk will suffer high load. After successful extraction
next tab Files and Paths will be displayed automatically.
Files and Paths tab is designed for source and output files specification. In case you previously used first tab for subtitle stream extraction the item File containing subtitle stream will be automatically filled out (pointing to just extracted subtitle stream). But if you start with this tab it is necessary to input here the complete path to the file on hard-disk containing extracted subtitle stream. Again Perl-Tk OpenFile dialog sometimes fails and the Browse... button must be used twice. The direct input (typing) is also possible.
In row Save final TXT subtitles as you can set directory and file name to which the final text subtitles should be saved. In case you do not specify any file here the final text subtitles will be saved in the same directory as stated in File containing DVD subtitles and with the same file name extended with .srt.
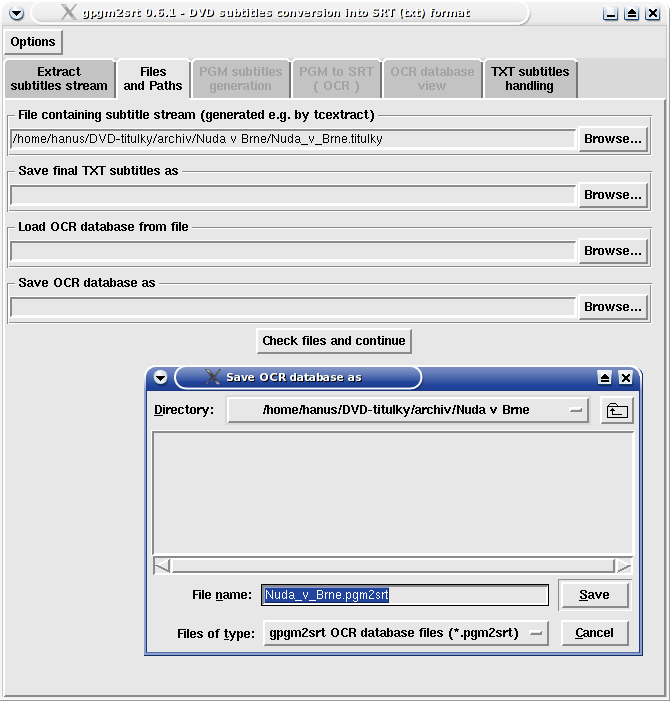
Load OCR database from file - loads previously saved OCR database. After successful load the
OCR database view tab will be available. Recognition algorithm used in this program (script) is based
on exact match of patterns, therefore it is not basically possible to use the same OCR database on different
subtitle streams. Saved OCR database can be used in case of necessity of repetitive processing of the same
subtitles stream.
Save OCR database as - OCR database containing recognized patterns and assigned chars will be
saved in this file (if not specified OCR database will not be saved).
After setting at least path for file containing subtitle stream click Check files and continue button. Script will check presence of input files, possibility of writing to output files and will move to PGM subtitles generation tab.
PGM subtitles generation tab helps to set parameters for subtitle2pgm. You can choose one of ten combinations in Choose -c parameter for subtitle2pgm area, the rest of combinations is de facto useless and only first four ones will be used mostly. Why this all? Subtitles are stored on DVD as pictures and the picture subtitle can be mixed with up to four colours. Basically grey scale is used (including white and black) for more smooth look. Using this setting tells subtitle2pgm what colours should be replaced with black (0) and white (255). Ensure that the displayed subtitles will not be poured (too bold, connected letters) and on the other hand too thin subtitles are not suitable too. Very important is the look of subtitles in italic.
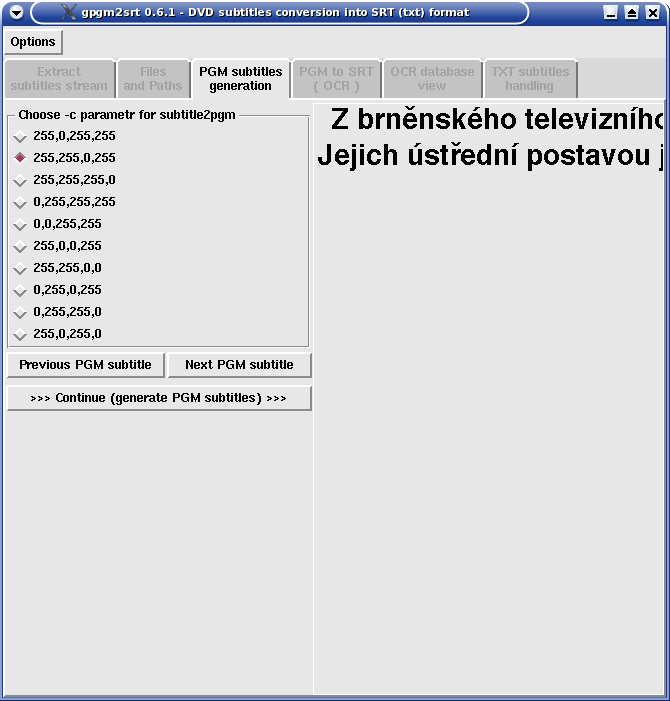
Using Previous PGM subtitle and Next PGM subtitle buttons you can shift in subtitles with approximately two minutes step (up to 60 minutes of subtitles) to enable search for italics in subtitles etc.
In case you are satisfied with -c parameter setting, press Continue (generate PGM subtitles) button and subtitle2pgm binary will be called. Example subtitle will be replaced with text asking you for patience. The process of generating PGM pictures with subtitles from subtitle stream is running. Depending on number of subtitles and power of you machine will this process take a couple tens of seconds. PGM subtitle pictures are saved into working directory i.e. hidden directory /.gpgm2srt/ in your home dir.
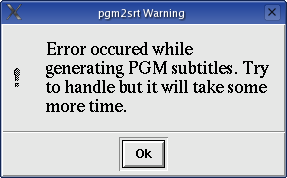 Some "problematic" subtitles can cause unexpected termination :o) of subtitle2pgm because of insufficient
handling of "crisis situations" during the program run - at least herein posted binary does so. In that case warning
window is displayed. After clicking OK my script will try solve this problem by several more complicated calls
of subtitle2pgm. This procedure is more time intensive (around 3-5 times more) compared to
non-problematic run of subtitle2pgm.
Some "problematic" subtitles can cause unexpected termination :o) of subtitle2pgm because of insufficient
handling of "crisis situations" during the program run - at least herein posted binary does so. In that case warning
window is displayed. After clicking OK my script will try solve this problem by several more complicated calls
of subtitle2pgm. This procedure is more time intensive (around 3-5 times more) compared to
non-problematic run of subtitle2pgm.
After successful generation of all PGM subtitle pictures the PGM to SRT - OCR tab is displayed. This tab encompasses the crucial feature of this my software - transformation of graphical subtitles into its text representation using on my own developed exact match OCR algorithm. Algorithm looks for character pattern (separate cluster of pixels), displays it and asks user for the textual representation of that pattern. Next time it finds exactly the same pixel pattern, previously inputted text is used. Sometimes incomplete character patterns are generated or more characters in one pattern could be found too.
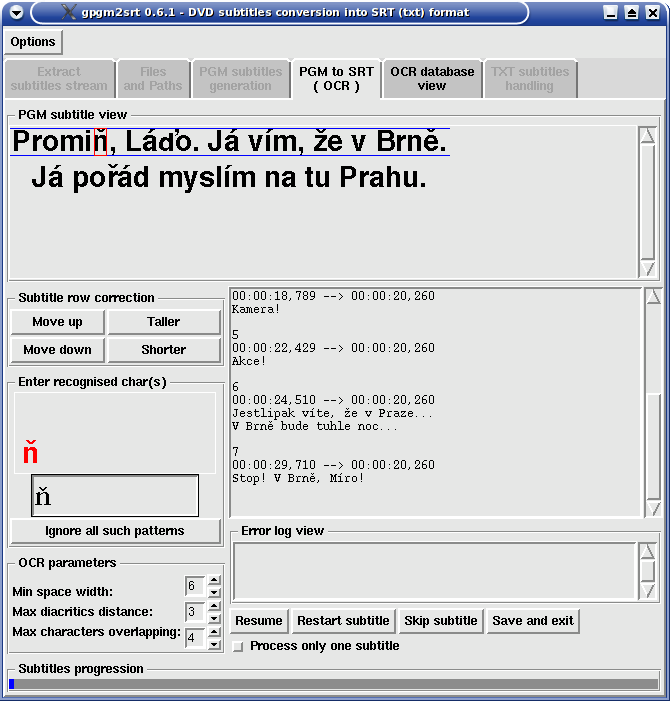
PGM subtitle view - here the subtitle preview is displayed where an unknown pattern was found; it would be every
subtitle at the beginning of the process. Blue lines highlight area of pixel rows which the algorithm detected as one row of text.
Sometimes it can be wrong and then manual correction is necessary using buttons in Subtitle row correction area. Red rectangle
marks area of pixels where the algorithm found unknown pattern - real look of recognized pattern is displayed in
Enter recognised char(s) area.
Move up - the button shifts both blue lines upwards. After required correction continue with Resume button.
Move down - shifts both blue lines downwards. After required correction continue with Resume button.
Taller - shifts bottom blue line downwards thus increasing the height of row. After required correction continue with Resume button.
Shorter - shifts bottom blue line upwards thus decreasing the height of row. After required correction continue with Resume button.
Enter recognised char(s) - in this area the real look of recognized pattern is displayed, this pattern is stored in
OCR database. Sometimes it is not the same as the content of red rectangle - especially in case of italics or some special
characters. If red displayed pattern matches say 80% of highlighted pixels there is high possibility that next patterns will
be recognized correctly. This area also contains text box where text representation of displayed pattern is inputted.
Ignore all such patterns - this button makes the displayed pattern to be ignored as next time is recognized (the pattern
is considered as empty character). If you wish to skip the recognized pattern only once just press ENTER (input empty character
into the text box). You will be prompted again next time the pattern will be recognized again.
Min space width - sets the minimum number of pixels to be considered as space character between words. If spaces inside
words are generated increase this number. If spaces between words are missing decrease this number.
Max diacritics distance - sets the maximum distance in pixels between characters and diacritics. If the diacritics are
not caught increase this number (usually no change is needed).
Max characters overlapping - sets the depth of letters overlapping in pixels - important for italics. When more letters
are often recognized as one pattern despite of they are not visually connected, increase the number.
Subtitle progression - shows the progression of subtitles processing.
Error log view - subtitles numbers where the algorithm encountered problems are printed here. Better check these
subtitles comparing them with corresponding picture subtitles - the algorithm might skip some letters.
Resume - continues the process of recognition after some parameters or text corrections.
Restart subtitle - displayed subtitle picture will be processed from the beginning (useful in case of different problems).
Skip subtitle - immediately skips to the next subpicture.
Save and exit - immediately stops the recognition process, saves hitherto recognized text subtitles (possibly OCR
database) and exits.
Process only one subtitle - only one picture subtitle is processed and displayed and text equivalent is printed, then
OCR process is paused thus allowing perfect control over OCR process in case of problematic subtitles. Continue with Resume
button.
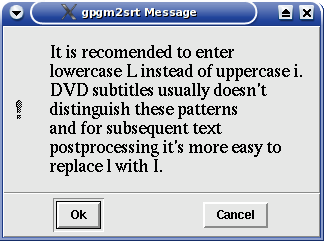 This warning/recommendation dialog is displayed when you input uppercase i as recognized char. Why?
Uppercase i and lowercase L have usually the same core appearance in graphical subtitles. And for subsequent
textual corrections it is easier to replace lowercase L with uppercase i where it makes mistake. Clicking OK makes automatic
change to lowercase L in input box. CANCEL leaves uppercase i inputted and accepts it after ENTER pressed.
This warning/recommendation dialog is displayed when you input uppercase i as recognized char. Why?
Uppercase i and lowercase L have usually the same core appearance in graphical subtitles. And for subsequent
textual corrections it is easier to replace lowercase L with uppercase i where it makes mistake. Clicking OK makes automatic
change to lowercase L in input box. CANCEL leaves uppercase i inputted and accepts it after ENTER pressed.
OCR database view tab is activated as soon as any character pattern is stored into memory (i.e. into OCR database), or previously saved OCR database was loaded from file. The tab shows the list of hitherto assigned characters to the different recognized patterns and allows the reassignment. List of characters assigned to patterns frame contains list of characters or strings inputted as the textual representation of recognized patterns during the process of recognition. DO NOT click inside this list (feature not yet implemented), just use scroll bar and |< and < or > and >| buttons to navigate through the list. The list is sorted by internal keys assigned to individual patterns, the last prompted pattern is displayed after tab appearance. Character highlighted in the list is displayed on the left in Assignment of recognized pattern frame together with the pattern (in red) which it was assigned to.
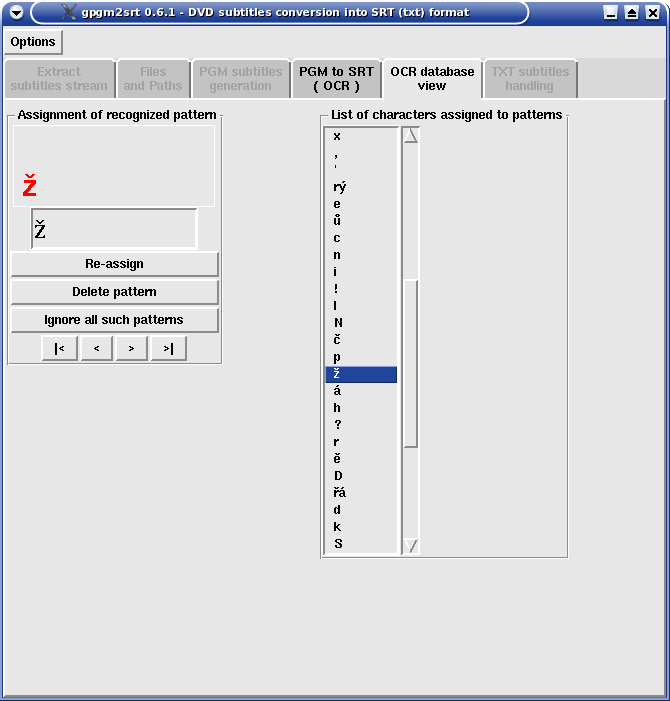
Re-assign - changes assignment for the displayed pattern to inputted character(s). This way you can
correct e.g. typos oops.
Delete pattern - deletes displayed pattern from OCR database (hash array in memory) thus next time
the algorithm recognizes such pattern it will prompt for textual assignment.
Ignore all such patterns - +ignore+ flag will be assigned to the displayed pattern. Such patterns
are automatically ignored/skipped during the process of recognition.
|< - skips to the first item in the List of characters.
< - moves up in the List of characters.
> - moves down in the List of characters.
>| - skips to the last item in the List of characters.
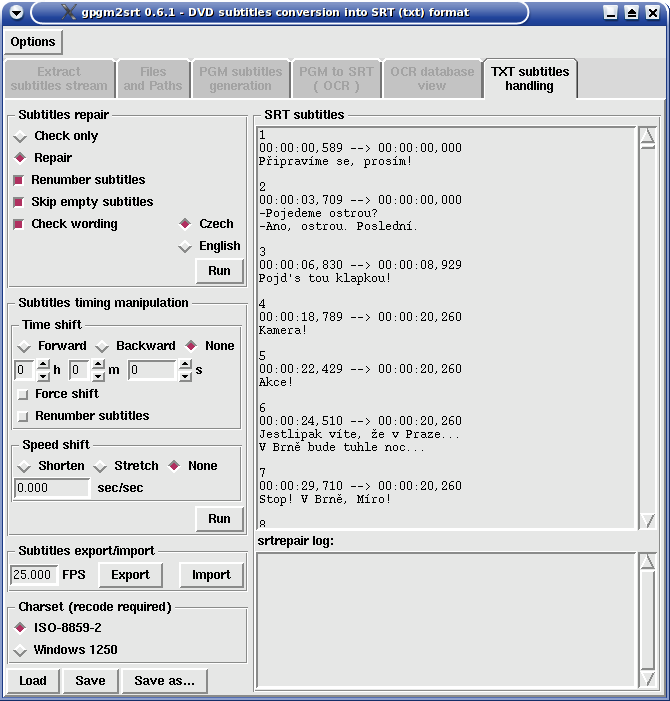
The last tab TXT subtitles handling is GUI for my srtrepair.pl Perl script appointed for post-OCR text subtitles corrections (timing correction and chars replacements). SRT and SUB text subtitles formats are supported, encoding in ISO-8859-2 or CP-1250.
Numbering of versions X.Y.Z: Z is changed with bugs repairs or other algorithm improvements. Change of Y comes with new features i.e. change in GUI. X will be changed very rarely - change of 0 to 1 will probably come with first rpm release (far far future).
Recommendation: download all the latest versions of scripts gpgm2srt.pl, Exactocr.pm, srtrepair.pl - look in the table below, scripts are updated independently.
Warning: Older Perl versions can file to compile use encoding ':locale'; command. In such case comment line with #, see Installation. Same approach can be tried in case of problems with saving/loading text subtitles encoded in UTF-8/ISO-2/Win1250.
Notifications: for e-mail notification on new versions, send email with subject "Subscribe gpgm2srt new_ver" to xhant04@centrum.cz.
| 11.1.2006 gpgm2srt.pl version 0.6.1 |
|
| 3.11.2005 gpgm2srt.pl version 0.5.2 |
|
| 20.10.2005 gpgm2srt.pl version 0.5.1 srtrepair.pl version 1.11 |
|
| 20.7.2005 gpgm2srt.pl betaversion 0.4.0 srtrepair.pl version 1.10 |
|
| 1.4.2005 gpgm2srt.pl version 0.3.1 |
|
|
1.2.2005 gpgm2srt.pl version 0.2.1 |
|
|
21.12.2004 gpgm2srt.pl version 0.1.1 Exactocr.pm version 0.1 |
First GUI version. |
Any comments, bug reports and requests for features are welcome at xhant04@centrum.cz
![]()
